
实验室服务器又出问题了,为了能够之后方便监控资源和定位服务器问题,这次在重装系统后设计了这套方案
- 操作系统:Ubuntu 24
- Web 查看端口:20000
- 目标:易部署、易运维、出问题能追到具体用户
- 范围:CPU / 内存 / 磁盘 / 网络 / GPU 资源监控 + 高危操作审计
其中 Prometheus 负责存储时间序列指标数据、Audit 记录 Linux 审计事件、Atop 记录系统和进程级活动历史;node_exporter 采集主机 CPU、内存、磁盘、网络等指标、dcgm-exporter 采集 NVIDIA GPU 指标,提供 /metrics;Grafana 作为唯一 Web 门户,端口 20000
各组件介绍
本系统奉行单入口、读写分离、架构轻量的原则,在不引入重型调度器的情况下,重点满足“看状态”与“能追责”。各核心组件功能边界如下:
1. 展示与视图层
- Grafana:作为唯一的 Web 门户(监听 20000 端口),对外提供统一的可视化看板。通过权限分级,让普通用户查看整机资源大盘(无敏感信息),管理员查看详细的用户及进程排障数据,实现前端与底层数据的隔离。
2. 资源监控层(指标采集与存储)
主要用于采集和存储时间序列状态数据(建议保留 15~30 天):
- Prometheus:核心时间序列数据库(TSDB),负责从各 exporter 抓取 metrics 数据并长期落盘存储,作为 Grafana 的查询数据源。
- node_exporter:负责采集服务器基础硬件层指标,包括 CPU 使用率/负载、内存剩余空间、磁盘 I/O 与系统网络吞吐等。
- dcgm-exporter:负责采集 NVIDIA GPU 的核心监控指标,涵盖各 GPU 的算力利用率、显存占用、功耗及温度等状态。
3. 用户追踪与行为审计层(日志与溯源)
主要负责高危行为留痕和历史异常回放,解决“出问题能找到对应责任人”的需求:
- auditd:Linux 核心级别的系统审计守护进程。负责记录提权(如
sudo)、敏感命令执行、配置文件(如 SSH、用户组)被篡改等高危操作。满足出故障时对误操作及违规操作的审查记录与追责功能。 - atop:强大的系统与进程级历史状态记录工具。周期性保存系统进程快照日志。当出现过往时段的资源打满死机或算力异常时,管理员可通过其历史日志精准定位耗尽资源的具体 PID、运行命令及对应用户。
部署方式
注意!:该服务器有 500g 系统固态盘 + 3 块 8T 机械盘,分别挂载为/home /data1 /data2,以下部署方式中出现的 /data1 /data2根据实际情况调整
创建日志目录
sudo mkdir -p /data2/prometheus
sudo mkdir -p /data2/audit
sudo mkdir -p /data2/atop
sudo mkdir -p /data2/reports
sudo chown -R prometheus:prometheus /data2/prometheus 2>/dev/null || true
sudo chmod 750 /data2/prometheus
安装基础包
sudo apt install -y prometheus prometheus-node-exporter auditd atop sysstat curl wget gnupg2 ca-certificates apt-transport-https
确认服务
systemctl status prometheus --no-pager
systemctl status prometheus-node-exporter --no-pager
systemctl status auditd --no-pager
systemctl status atop --no-pager
添加 Grafana 官方源
sudo mkdir -p /etc/apt/keyrings
sudo wget -O /etc/apt/keyrings/grafana.asc https://apt.grafana.com/gpg-full.key
sudo chmod 644 /etc/apt/keyrings/grafana.asc
echo "deb [signed-by=/etc/apt/keyrings/grafana.asc] https://apt.grafana.com stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
sudo apt update
安装 Grafana
sudo apt install -y grafana
修改 Grafana 监听端口
sudo cp /etc/grafana/grafana.ini /etc/grafana/grafana.ini.bak
sudo sed -i 's/^;http_port = 3000/http_port = 20000/' /etc/grafana/grafana.ini
grep -n "^http_port" /etc/grafana/grafana.ini
开放 端口
sudo ufw allow 20000/tcp
启动并设置开机自启动
sudo systemctl daemon-reload
sudo systemctl enable --now grafana-server
sudo systemctl status grafana-server --no-pager
备份 Prometheus 配置并写入新配置
sudo cp /etc/prometheus/prometheus.yml /etc/prometheus/prometheus.yml.bak
sudo tee /etc/prometheus/prometheus.yml > /dev/null <<'EOF'
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['127.0.0.1:9090']
- job_name: 'node'
static_configs:
- targets: ['127.0.0.1:9100']
- job_name: 'dcgm'
static_configs:
- targets: ['127.0.0.1:9400']
EOF
修改 Prometheus systemd 启动参数
sudo mkdir -p /etc/systemd/system/prometheus.service.d
sudo tee /etc/systemd/system/prometheus.service.d/override.conf > /dev/null <<'EOF'
[Service]
ExecStart=
ExecStart=/usr/bin/prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/data2/prometheus \
--storage.tsdb.retention.time=15d \
--web.listen-address=127.0.0.1:9090
EOF
重载并启动
sudo systemctl daemon-reload
sudo systemctl restart prometheus
sudo systemctl enable prometheus
sudo systemctl status prometheus --no-pager
权限部分修复
sudo mkdir -p /data2/prometheus
sudo chown -R prometheus:prometheus /data2/prometheus
sudo chmod 750 /data2/prometheus
sudo chmod 755 /data2
namei -l /data2/prometheus
sudo mkdir -p /etc/apparmor.d/local
sudo tee /etc/apparmor.d/local/usr.bin.prometheus > /dev/null <<'EOF'
/data2/prometheus/ rw,
/data2/prometheus/** rwk,
EOF
sudo apparmor_parser -r /etc/apparmor.d/usr.bin.prometheus
sudo apparmor_parser -r /etc/apparmor.d/usr.bin.prometheus
sudo systemctl restart prometheus
sudo systemctl status prometheus --no-pager -l
curl -s http://127.0.0.1:9090/-/healthy
配置 node_exporter 只监听本机
sudo mkdir -p /etc/systemd/system/prometheus-node-exporter.service.d
sudo tee /etc/systemd/system/prometheus-node-exporter.service.d/override.conf > /dev/null <<'EOF'
[Service]
ExecStart=
ExecStart=/usr/bin/prometheus-node-exporter --web.listen-address=127.0.0.1:9100
EOF
sudo systemctl daemon-reload
sudo systemctl restart prometheus-node-exporter
sudo systemctl enable prometheus-node-exporter
sudo systemctl status prometheus-node-exporter --no-pager
配置 docker
sudo apt install -y ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] http://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo vim /etc/docker/daemon.json
改为:
{
"registry-mirrors": [
"https://docker.1ms.run"
]
}
sudo systemctl restart docker
安装 NVIDIA Container Toolkit
sudo apt-get update && sudo apt-get install -y --no-install-recommends ca-certificates curl gnupg2
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
sudo docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
部署 dcgm-exporter,并限制为本机监听
sudo tee /etc/systemd/system/dcgm-exporter.service > /dev/null <<'EOF'
[Unit]
Description=DCGM Exporter for Prometheus
Requires=docker.service
After=docker.service
[Service]
Type=simple
Environment=DCGM_EXPORTER_VERSION=2.1.4-2.3.1
ExecStartPre=-/usr/bin/docker rm -f dcgm-exporter
ExecStart=/usr/bin/docker run --rm --name dcgm-exporter \
--gpus all \
--net host \
--cap-add SYS_ADMIN \
nvcr.io/nvidia/k8s/dcgm-exporter:${DCGM_EXPORTER_VERSION}-ubuntu20.04 \
-a 127.0.0.1:9400 \
-f /etc/dcgm-exporter/dcp-metrics-included.csv
ExecStop=/usr/bin/docker stop dcgm-exporter
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable --now dcgm-exporter
sudo systemctl status dcgm-exporter --no-pager
ss -lntp | grep 9400
curl -s http://127.0.0.1:9400/metrics | head
配置 auditd,把日志放到 /data2/audit
sudo mkdir -p /data2/audit
sudo chown root:root /data2/audit
sudo chmod 700 /data2/audit
sudo cp /etc/audit/auditd.conf /etc/audit/auditd.conf.bak
sudo sed -i 's#^log_file = .*#log_file = /data2/audit/audit.log#' /etc/audit/auditd.conf
sudo sed -i 's/^max_log_file = .*/max_log_file = 100/' /etc/audit/auditd.conf
sudo sed -i 's/^num_logs = .*/num_logs = 20/' /etc/audit/auditd.conf
sudo sed -i 's/^max_log_file_action = .*/max_log_file_action = ROTATE/' /etc/audit/auditd.conf
sudo tee /etc/audit/rules.d/server-monitor.rules > /dev/null <<'EOF'
## 用户与身份文件
-w /etc/passwd -p wa -k identity
-w /etc/shadow -p wa -k identity
-w /etc/group -p wa -k identity
-w /etc/gshadow -p wa -k identity
-w /etc/sudoers -p wa -k scope
-w /etc/sudoers.d/ -p wa -k scope
## SSH、防火墙、systemd
-w /etc/ssh/sshd_config -p wa -k sshd
-w /etc/ufw/ -p wa -k firewall
-w /etc/systemd/system/ -p wa -k systemd
-w /lib/systemd/system/ -p wa -k systemd
## 关键命令
-a always,exit -F arch=b64 -S execve -F euid=0 -k privileged-cmd
-a always,exit -F arch=b64 -S chmod,fchmod,fchmodat,chown,fchown,fchownat,lchown -k perm_mod
-a always,exit -F arch=b64 -S unlink,unlinkat,rename,renameat,rmdir -k delete_ops
EOF
sudo augenrules --load
sudo systemctl restart auditd
sudo systemctl enable auditd
sudo systemctl status auditd --no-pager
sudo true
sudo ausearch -k privileged-cmd | tail
sudo aureport -x --summary | head
配置 atop,并把历史日志落到 /data2/atop
sudo mkdir -p /data2/atop
sudo chown root:root /data2/atop
sudo chmod 755 /data2/atop
sudo cp /etc/default/atop /etc/default/atop.bak
cat /etc/default/atop
sudo systemctl stop atop
sudo systemctl stop atopacct
sudo mv /var/log/atop /var/log/atop.bak
sudo ln -s /data2/atop /var/log/atop
sudo systemctl start atopacct
sudo systemctl start atop
sudo systemctl status atop --no-pager
sudo systemctl status atopacct --no-pager
ls -ld /var/log/atop
ls -lah /data2/atop
把 Grafana 接上 Prometheus
Grafana 安装好后,浏览器访问:
默认账号通常是:
admin
admin
然后添加数据源:
类型:Prometheus
URL:http://127.0.0.1:9090
Save & Test
Grafana 配置
创建两个 DashBoard,一份面向普通用户,一份面向管理员
Public:
- Panel 1: CPU Usage
- PromQL:
100 * (1 - avg(rate(node_cpu_seconds_total{mode="idle"}[5m]))) - Visualizations: Stat
- Unit: percent (0-100)
- PromQL:
如图:PromQL 配置时需要选用 Code 模式,填写完成后点击 Run queries
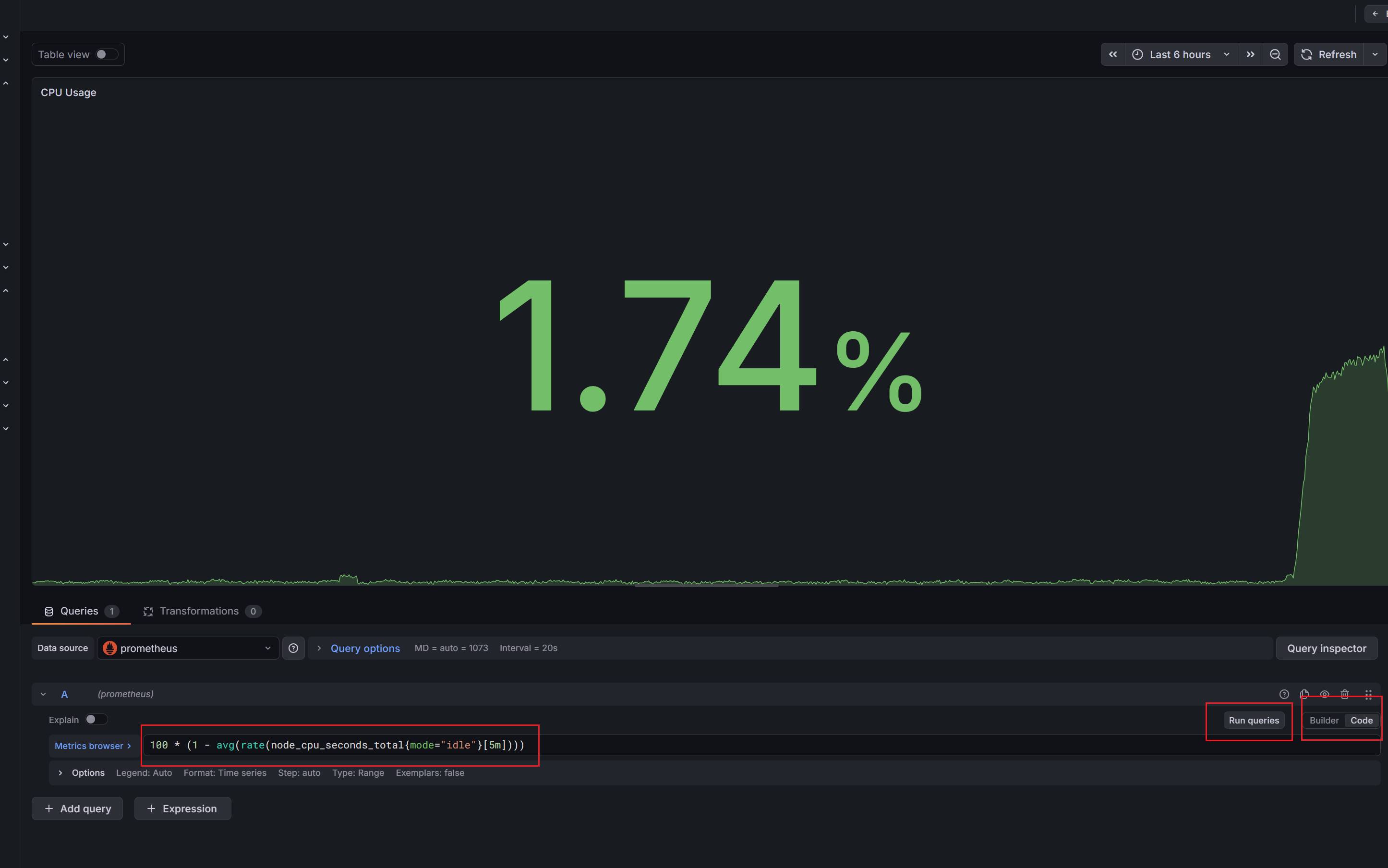
-
Panel 2: Memory Usage
- PromQL:
100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) - Visualizations: Stat
- Unit: percent (0-100)
- PromQL:
-
Panel 3: Root Filesystem Usage
- PromQL:
100 * (1 - (node_filesystem_avail_bytes{mountpoint="/",fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{mountpoint="/",fstype!~"tmpfs|overlay"})) - Visualizations: Stat
- Unit: percent (0-100)
- PromQL:
-
Panel 4: /data1 Usage
- PromQL:
100 * (1 - (node_filesystem_avail_bytes{mountpoint="/data1",fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{mountpoint="/data1",fstype!~"tmpfs|overlay"})) - Visualizations: Stat
- Unit: percent (0-100)
- PromQL:
-
Panel 5: /data2 Usage
- PromQL:
100 * (1 - (node_filesystem_avail_bytes{mountpoint="/data2",fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{mountpoint="/data2",fstype!~"tmpfs|overlay"})) - Visualizations: Stat
- Unit: percent (0-100)
- PromQL:
-
Panel 6: Network Traffic
- PromQL1:
sum(rate(node_network_receive_bytes_total{device!~"lo"}[5m])) - PromQL2:
sum(rate(node_network_transmit_bytes_total{device!~"lo"}[5m])) - Visualizations: Time series
- Unit: bytes/sec
- PromQL1:
-
Panel 7: GPU Utilization
- PromQL:
100 * clamp_min(clamp_max((DCGM_FI_DEV_POWER_USAGE - 25) / (349 - 25), 1), 0) - Visualizations: Time series
- Unit: percent (0-100)
由于无法直接获取显卡使用时负载百分比,所以通过粗略计算功耗的方式来实现,该服务器为 3090 350W,上机后 4 张卡最低功耗维持在 9-25W,因此使用这种形式来表达
- PromQL:
-
Panel 8: GPU Memory Usage
- PromQL:
DCGM_FI_DEV_FB_USED - Visualizations: Time series
- Unit: mebibytes (MiB)
- PromQL:
Admin:
-
Panel 1: CPU Usage Over Time
- PromQL:
100 * (1 - avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]))) - Visualizations: Time series
- Unit: percent (0-100)
- PromQL:
-
Panel 2: System Load
- PromQL 1:
node_load1 - PromQL 2:
node_load5 - PromQL 3:
node_load15 - Visualizations: Time series
- Unit: percent (0-100)
- PromQL 1:
-
Panel 3: Disk Read/Write
- PromQL Read:
sum(rate(node_disk_read_bytes_total[5m])) - PromQL Write:
sum(rate(node_disk_written_bytes_total[5m])) - Visualizations: Time series
- Unit: bytes/sec
- PromQL Read:
-
Panel 4: CPU IOWait
- PromQL:
100 * avg(rate(node_cpu_seconds_total{mode="iowait"}[5m])) - Visualizations: Time series
- Unit: percent (0-100)
- PromQL:
-
Panel 5: GPU Power Usage
- PromQL:
DCGM_FI_DEV_POWER_USAGE - Visualizations: Time series
- Unit: Watt(W)
- PromQL:
-
Panel 6: GPU SM Clock
- PromQL:
DCGM_FI_DEV_SM_CLOCK - Visualizations: Time series
- Unit: MHz
- PromQL:
-
Panel 7: GPU Memory Detail
- PromQL:
100 * (DCGM_FI_DEV_FB_USED / DCGM_FI_DEV_FB_TOTAL) # 或者仅使用 DCGM_FI_DEV_FB_USED - Visualizations: Time series
- PromQL:
-
Panel 8: GPU Temperature
- PromQL:
DCGM_FI_DEV_GPU_TEMP - Visualizations: Time series
- Unit: °C
- PromQL:
-
Panel 9: Host Up
- PromQL:
up - Visualizations: Stat (值为 1 说明正常)
- PromQL:
最终监控看板效果呈现
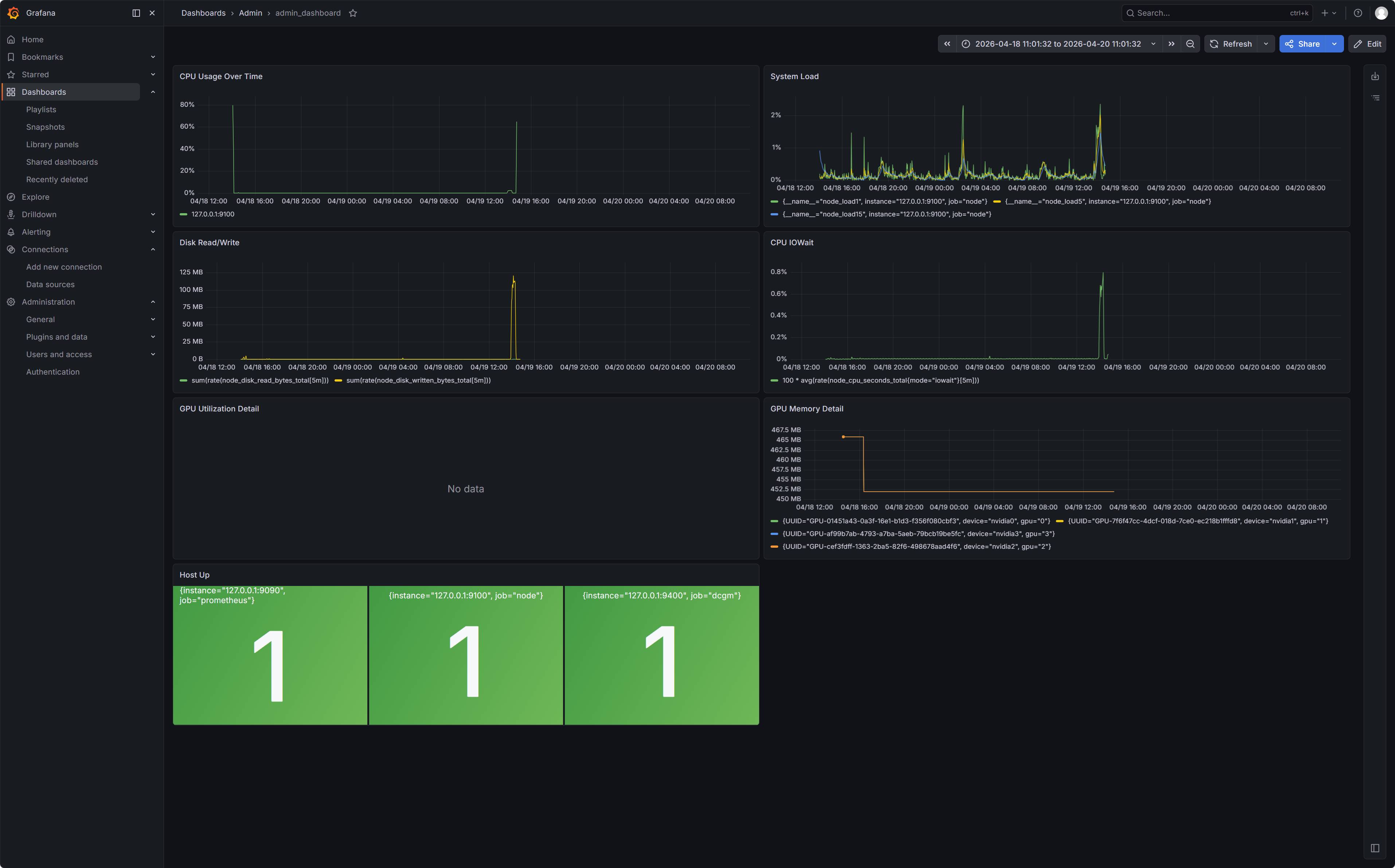
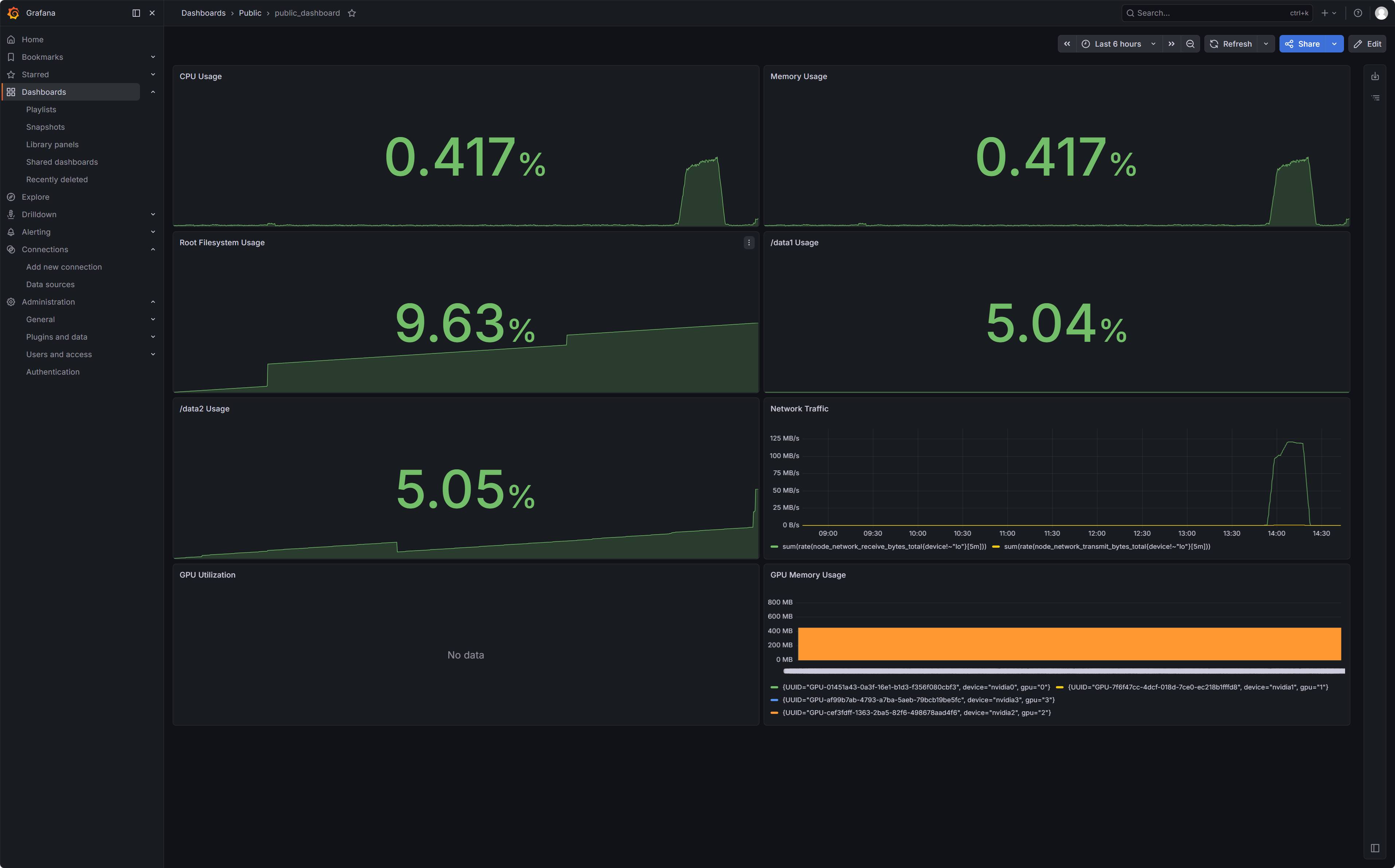


评论区