
1 简介
GPT-SoVITS 是 b 站 up 主花儿不哭开发的一款文本转语音(tts)开源项目,对比 VITS 等之前的 tts 项目具有训练时间短,数据集需求少,易使用等优点。
2 部署
2.1 Windows 一键部署
为了便于用户使用,项目作者已经准备好了项目整合包,不需要自己配置环境,解压后双击 go-webui.bat 即可启动 GPT-SoVITS-WebUI。整合包下载
2.2 Windows&Linux 配置环境使用
前置条件:安装 Anaconda,git 并确保环境变量配置成功
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
cd GPT-SoVITS
conda create -n GPTSoVits python=3.9
conda activate GPTSoVitsLinux
bash install.shWindows
pip install -r requirements.txt下载 ffmpeg.exe 并将其放在 GPT-SoVITS 的根目录下
3 音频处理
整合包可以通过双击go-webui.bat直接启动,如果是自己手动配置的需要在对应目录下通过命令行输入
python webui.py启动后会自动打开默认浏览器并建立并打开http://localhost:9874/的一个标签页,如下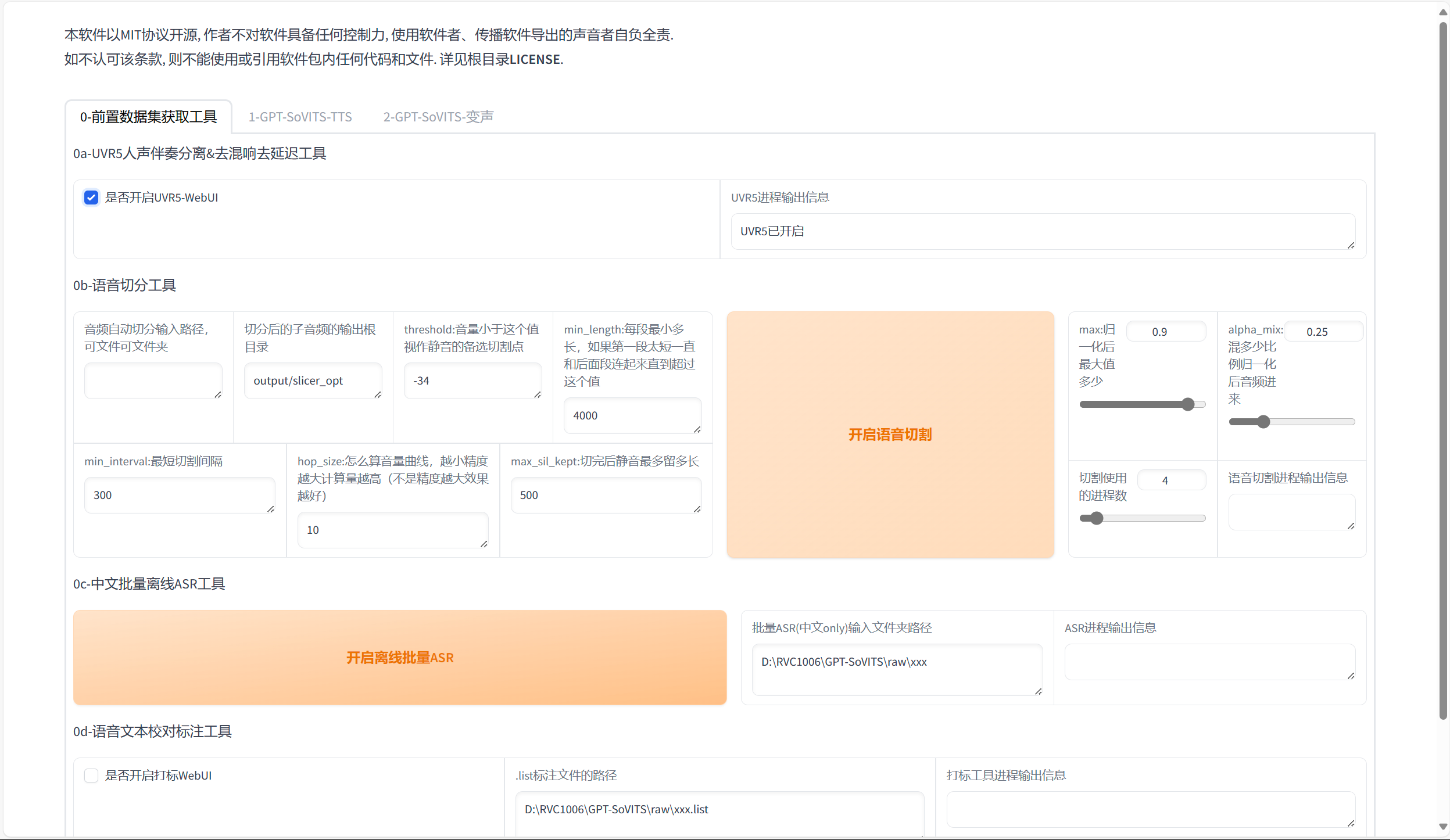
为了能够训练一个特定声音的模型,我们可以提前准备好一段wav格式的音频,至少一分钟的人物干声。建议在GPT-SoVITS根目录下建立一个专门用于音频处理的目录。
例如,我建立了一个名为 Voice 的目录,在其中又建立了几个对应的子目录
我们收集的音频并不能够直接使用,需要经过去噪,切片,打标三个流程。将音频文件放到了第一个目录下(目录下可以放置多段音频),复制 “01DataRaw” 目录的地址,开启 UVR5-WebUI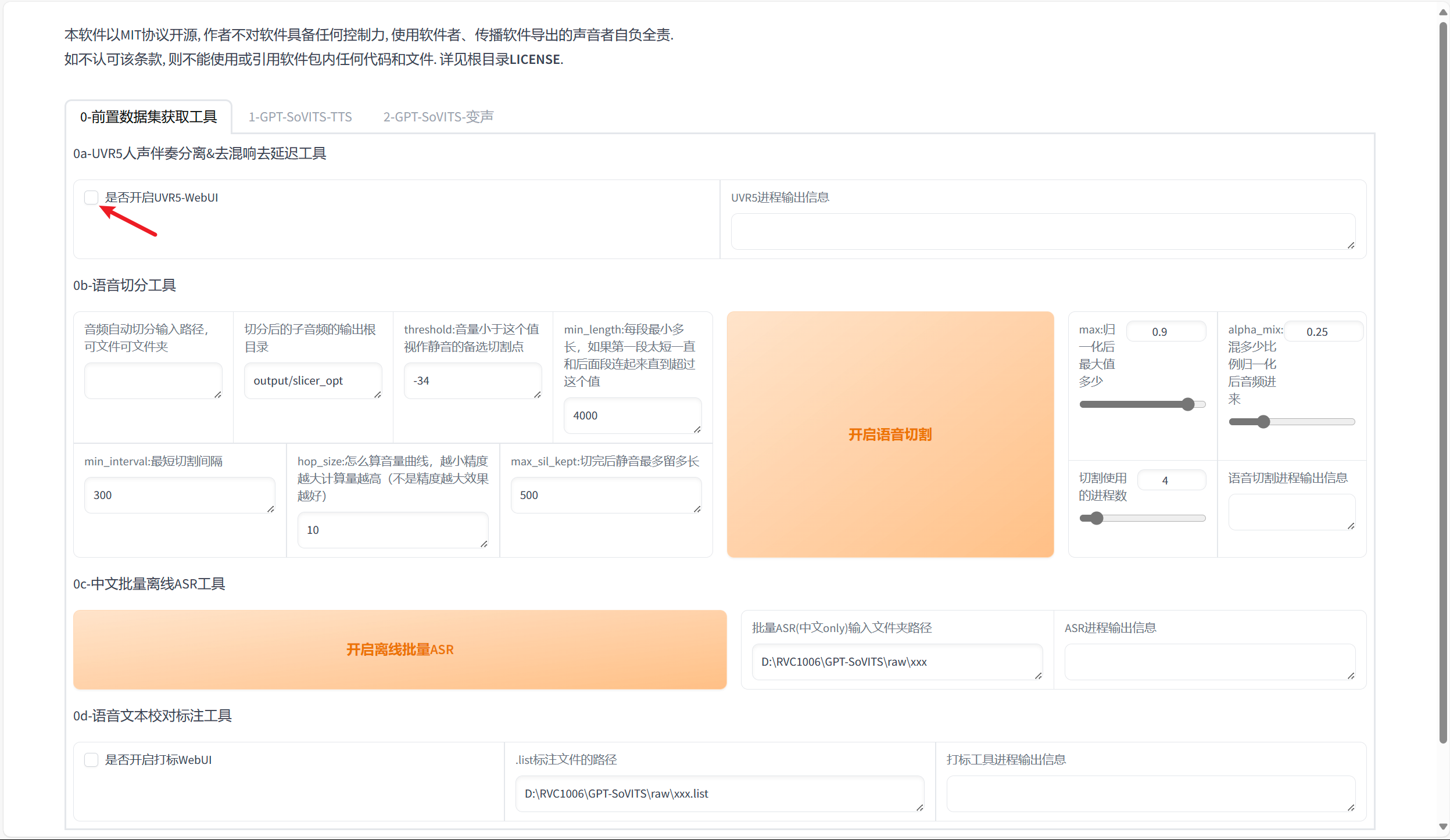
等待一段时间后自动跳转至UVR5去噪界面,如下
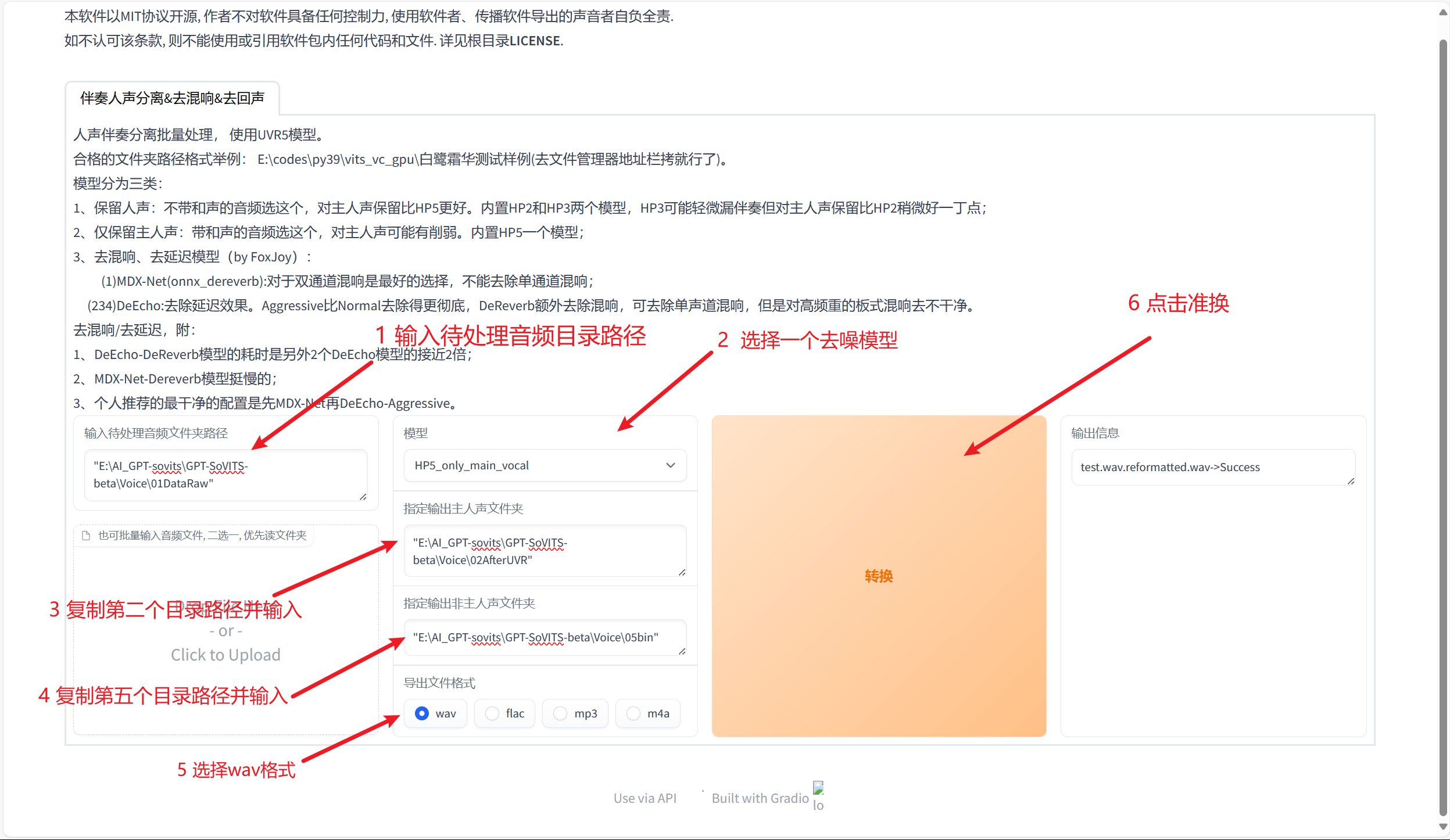
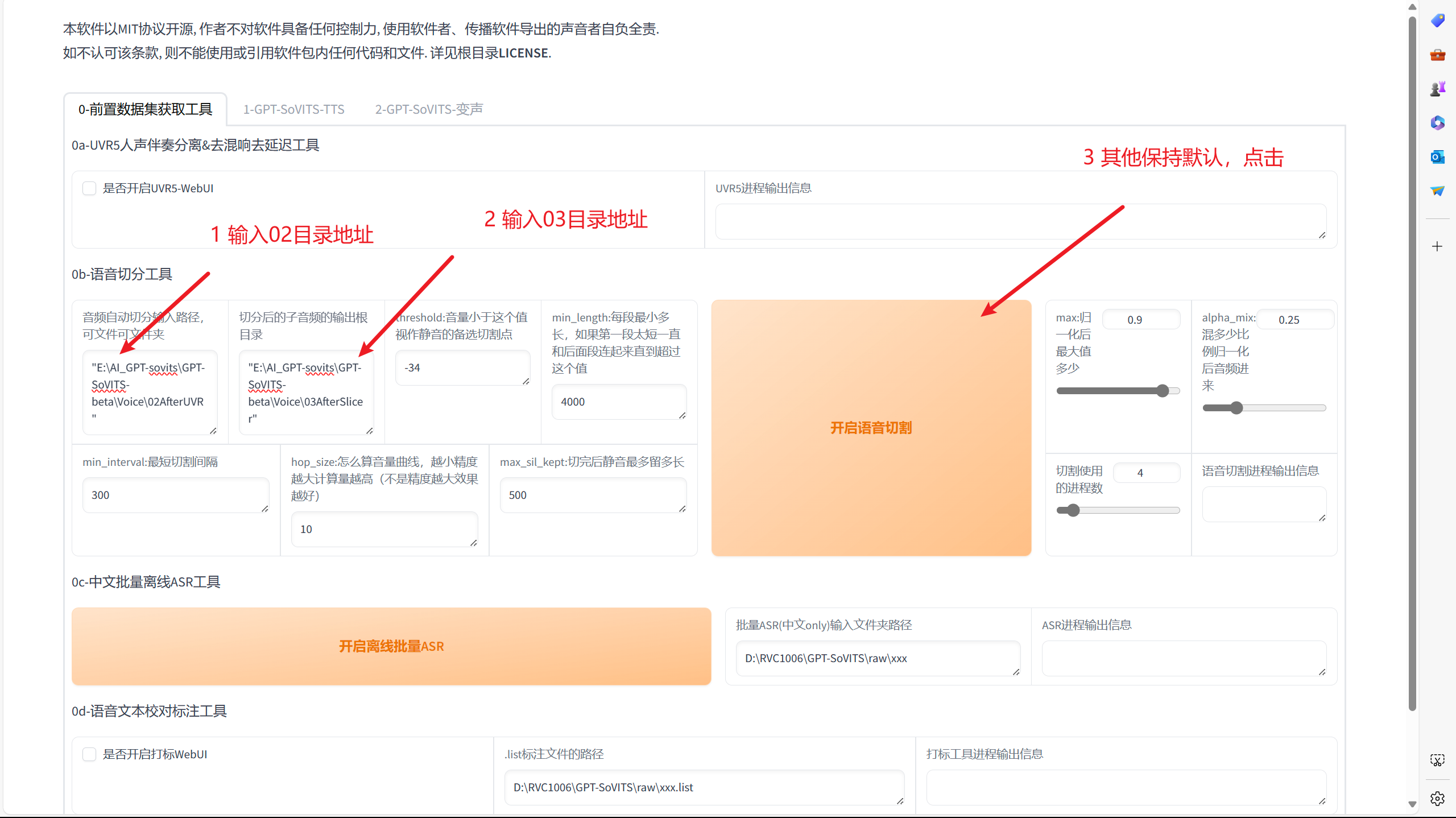
去噪完成,切回到该界面,按照下图进行操作进行语音切割
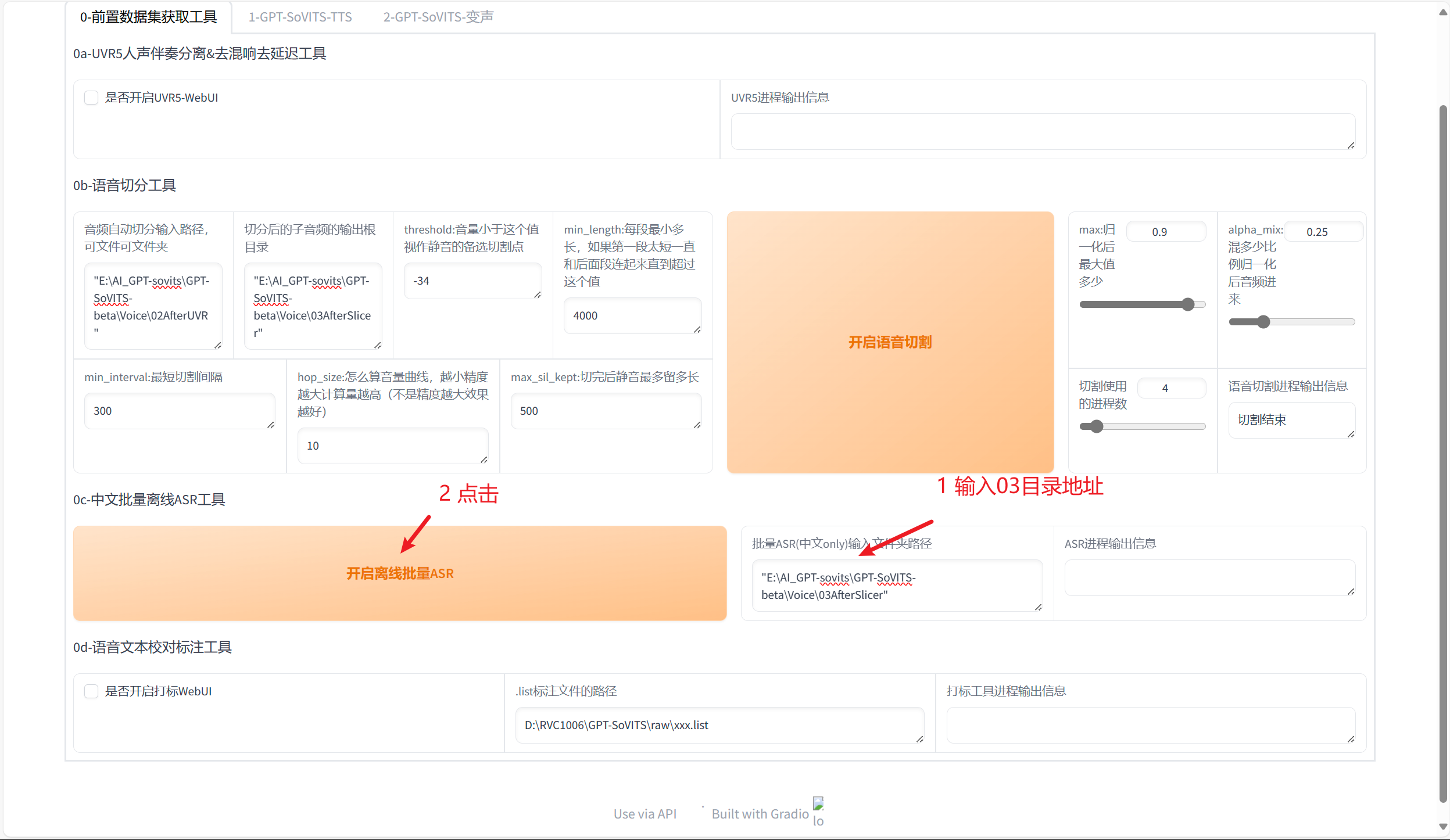
打标进程结束后,生成的打标文件会在根目录的 output>asr_opt 中,进入到该目录中我们可以找到一个.list扩展名的文件,复制它的地址。我们可以选择是否进行校对,如果需要,将它输入到下方的文本框当中,再点击左下方“是否开启打标WebUI“,根据提示操作即可。
4 训练
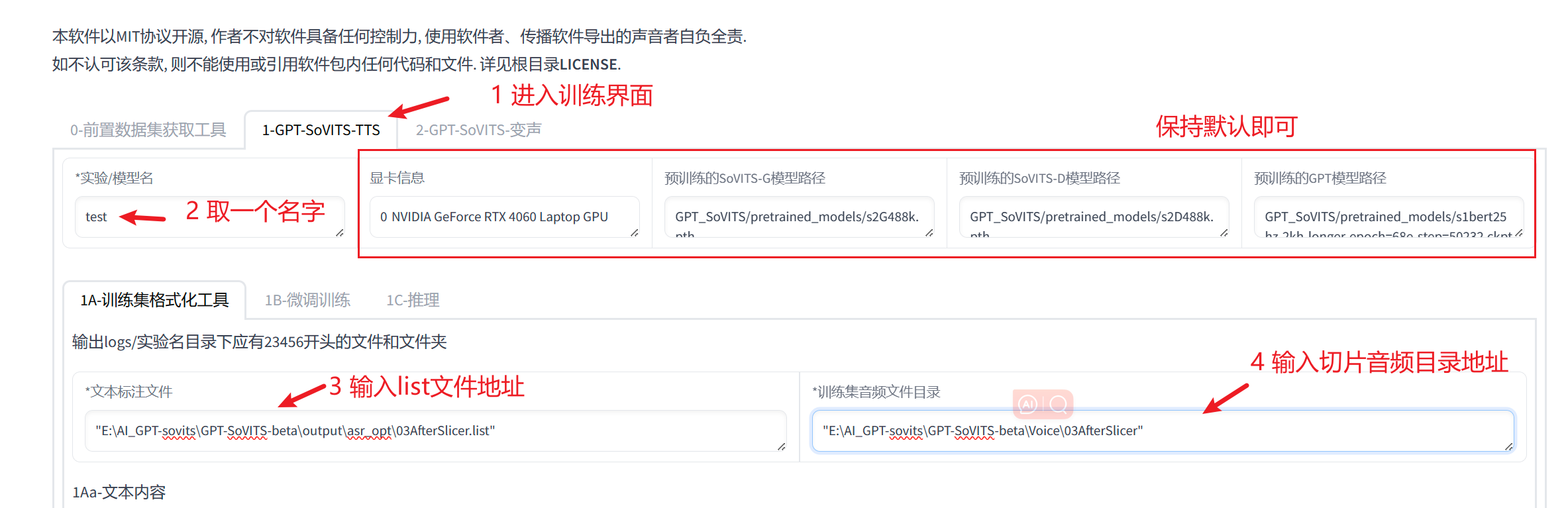
进入训练界面中,根据下图填写一些基本信息
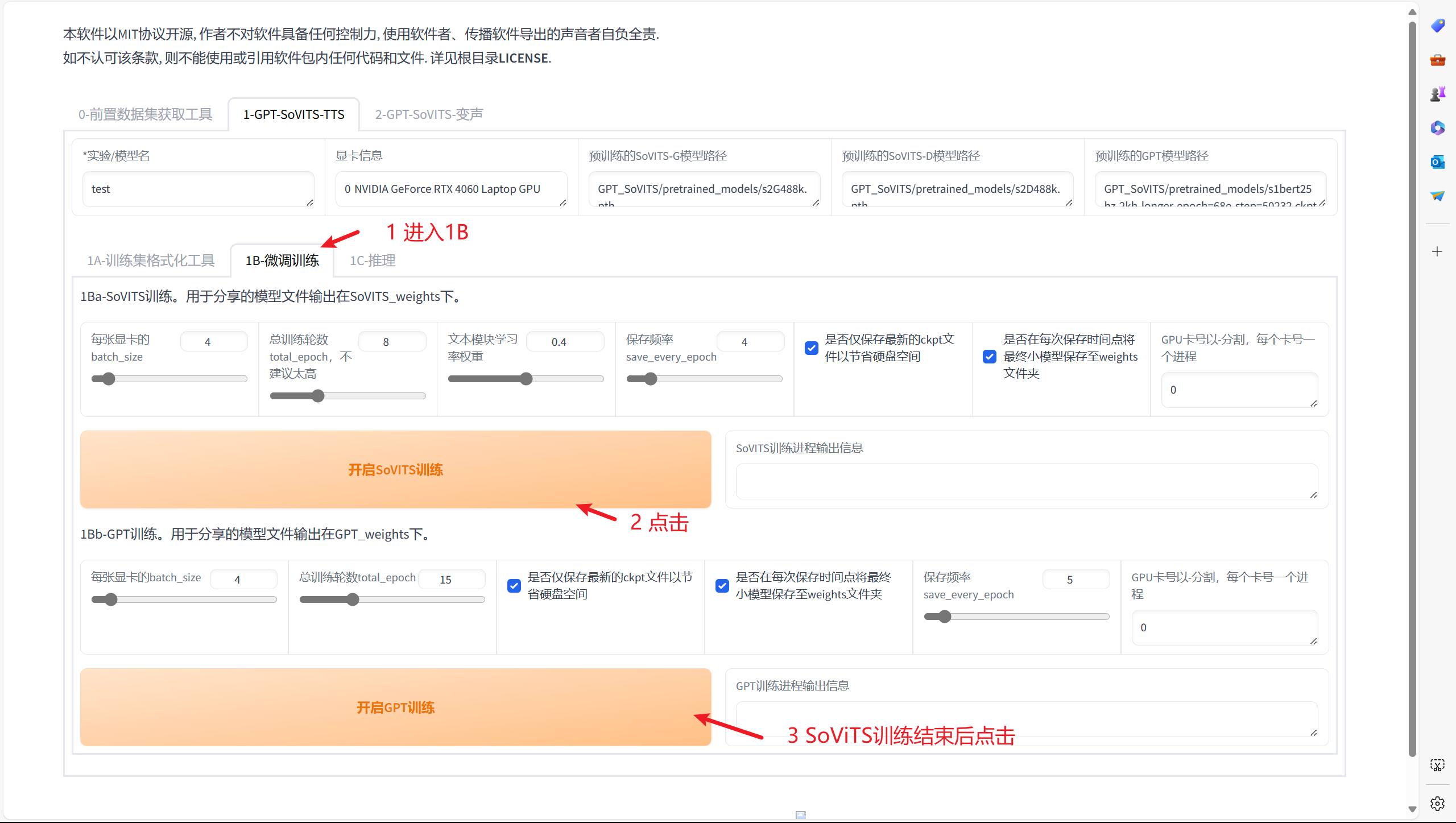
下滑,找到该按钮点击并等待

一键三连完成后开始正式进行训练,这里有许多参数,可以直接默认,不进行更改
5 推理
训练结束后进入推理界面
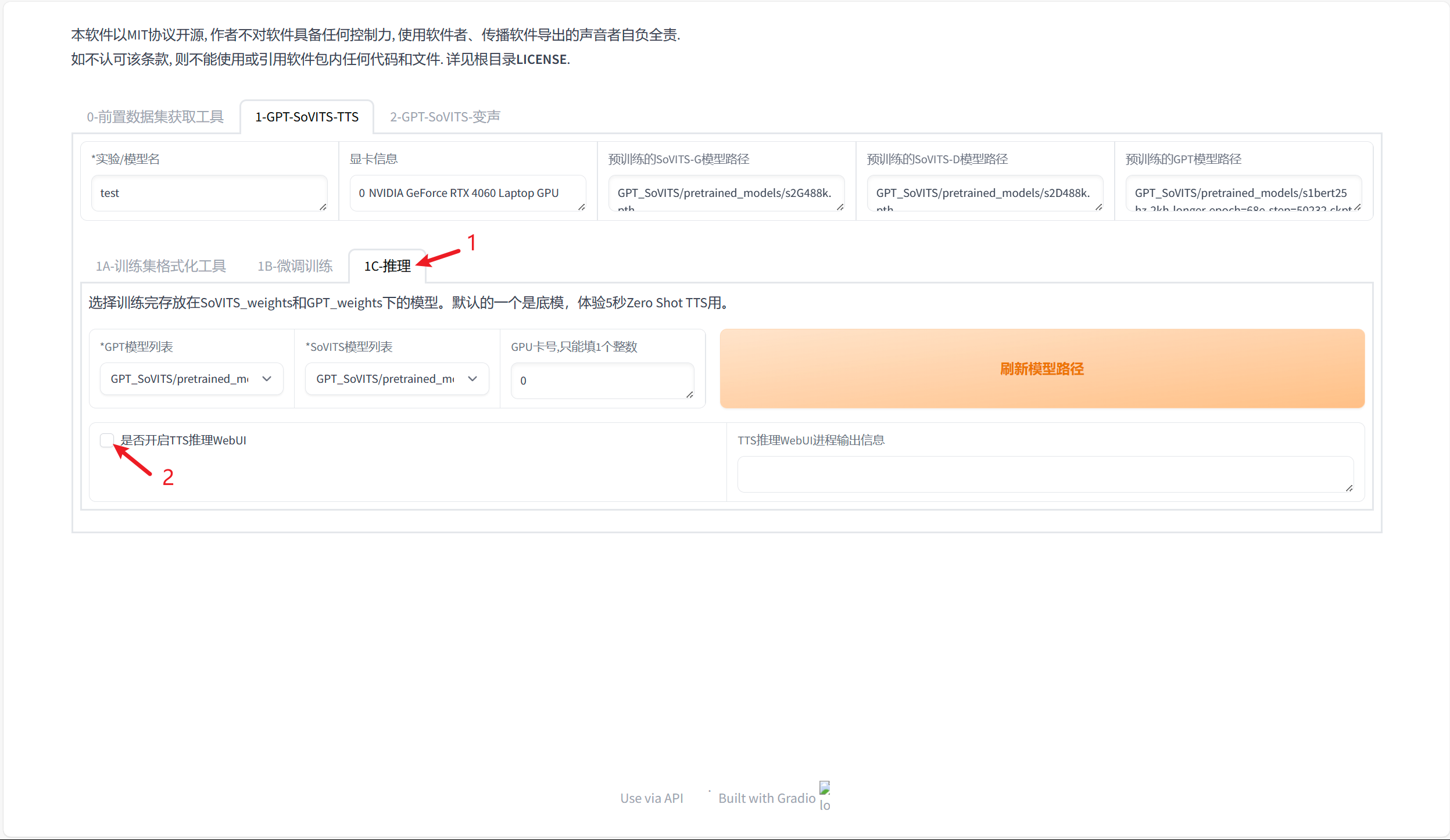
等待一段时间会开启一个新的标签页,
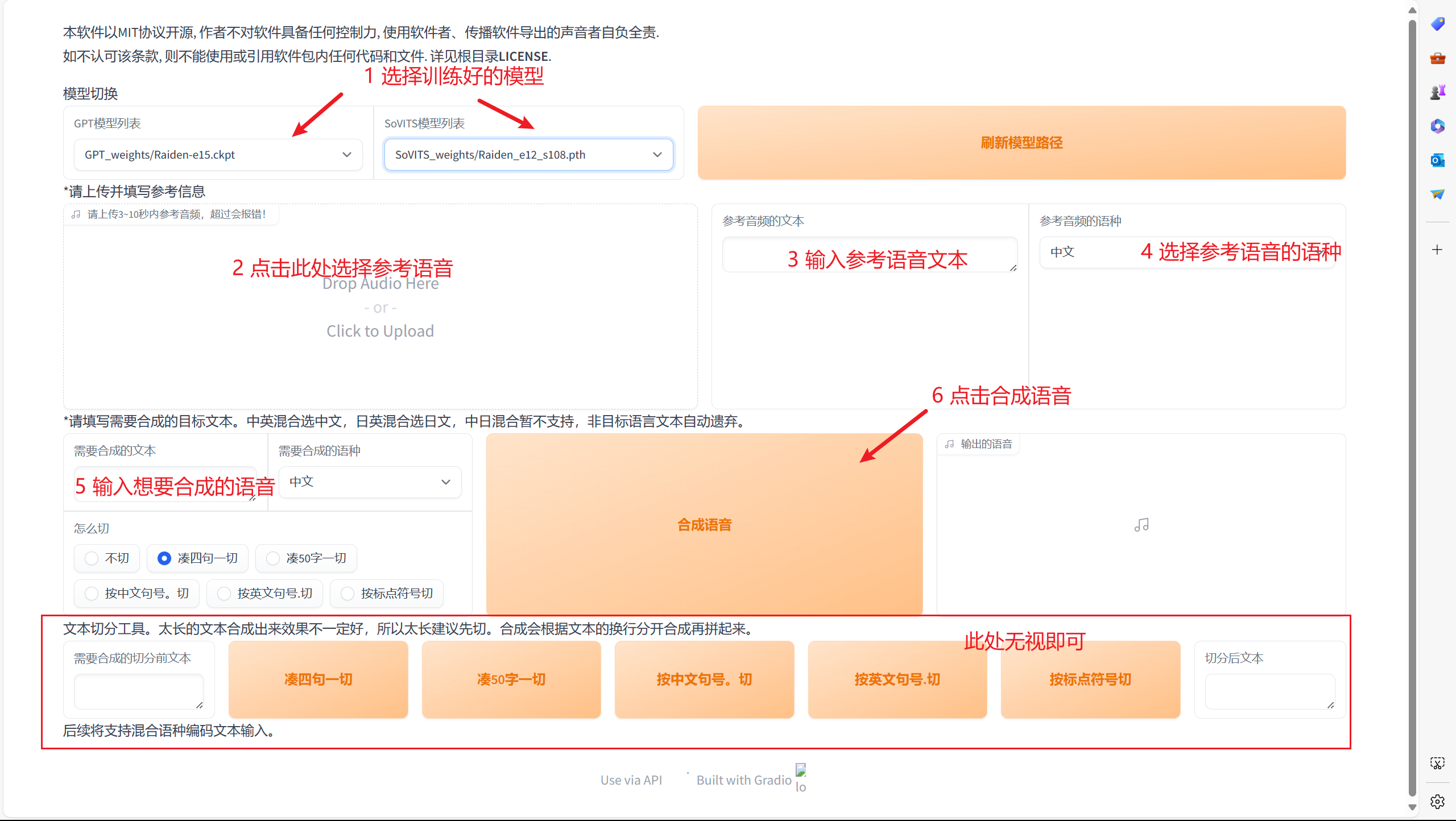
按照下图进行操作即可得到生成的语音
6 拓展应用——通过调用API搭建一个语音聊天机器人
为了实现这一功能,我们需要完成两部分:
通过 API 方式调用 GPT-SoVITS 而非 WebUI;
使用 moonshot 的 API 建立聊天机器人。
6.1 GPT-SoVITS_API 模式
这里我们使用 0207 版本的整合包,正常情况下我们都通过 WebUI 来使用 GPT-SoVITS,因为这样具有直观,便于交互等优点,但是我们要搭建聊天机器人就要将上面的操作批量自动进行,因此就要使用API的调用方式,便于开发,作者明显考虑到了这一情况,在项目目录下的api.py已经准备好了,我们只需要简单修改一些代码就可以使用了。
建立api启动脚本
在启动 webui 时,我们需要双击 go-webui.bat , bat 是一个批处理文件,能够批量执行 Windows 命令,那么我们要启动 api.py,我们就可以将 go-webui.bat 复制一份并命名为 go-api.bat,右键选择使用记事本进行编辑,我们可以就看到
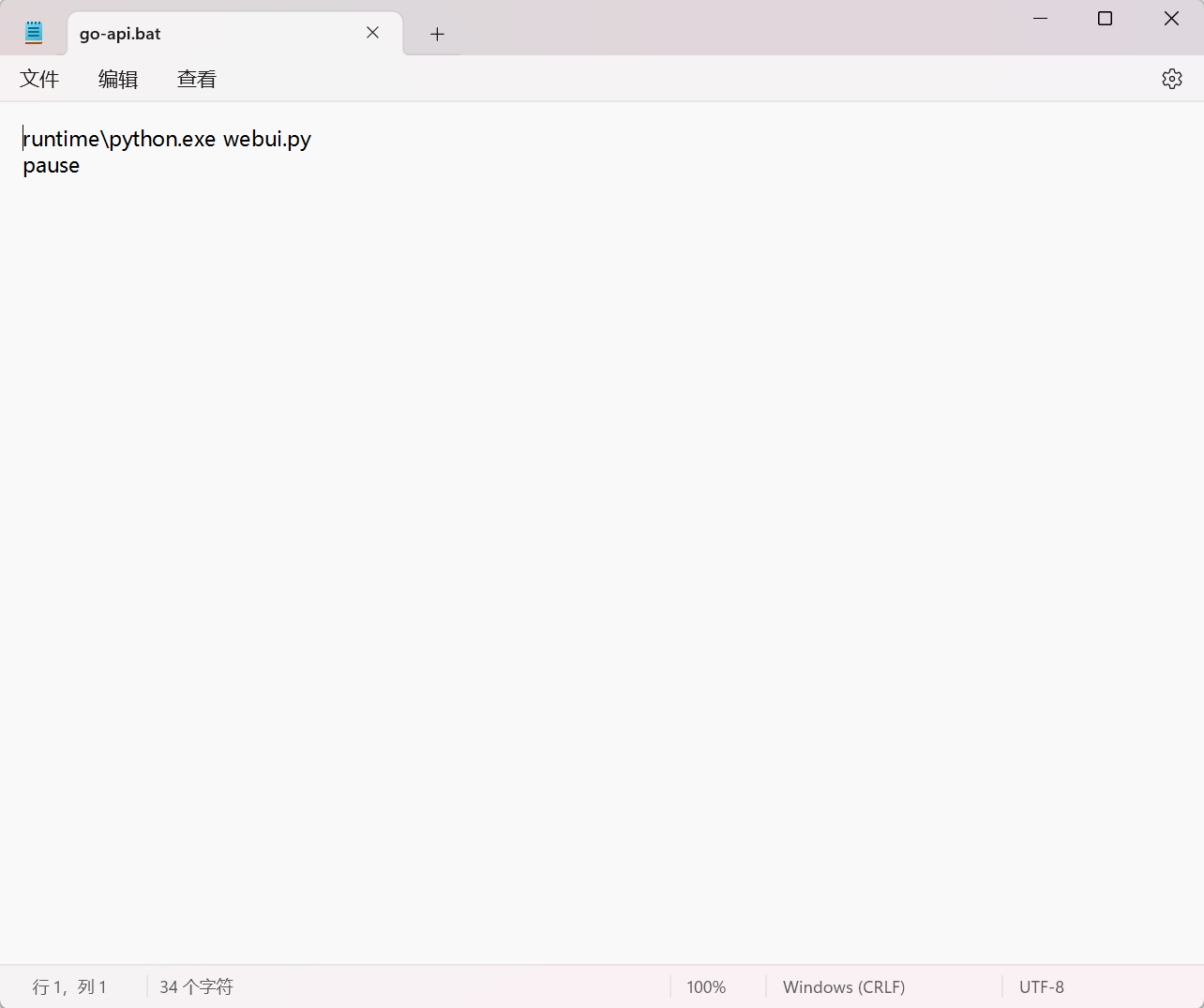
这段代码的意思是使用 runtime 下的 python 启动 webui.py,那么我们只需要把 webui.py 换成 api.py 就可以像启动 webui 一样启动 api 了
添加切分功能
使用 GPT-SoVITS 时为了避免爆显存,我们可以将想要推理的句子进行切分,使其多次进行,那么就像需要我们去对代码进行一些修改。
在 api.py 的 319 行有一个 get_tts_wav 的函数,因为推理部分中也有这一函数,且此处的代码功能相对单一,我们可以选择直接将这一函数注释掉或删掉,并使用推理部分的函数。
首先在 api.py 开头部分加入
from inference_webui import get_tts_wav为了防止 inference_webui.py 启动,我们要找到项目根目录下的 GPT-SoVITS 中的 inference_webui.py,然后在SoVITS_names, GPT_names = get_weights_names()后一行加入
def main():选中之后的代码集体缩进一下,并在最后加入
if __name__ == "name":
main()当然也可以直接注释掉。
这样我们就完成了对该函数的调用,然后就可以对该函数进行修改了。
找到 get_tts_wav 这一函数,代码默认不对文本进行切分,我们可以选择将其改为"凑四句一切",改完如图

指定模型位置
接下来,我们将修改api默认使用模型的路径,找到项目根目录下的config.py,根据自己模型放置的位置对 sovits_path 和 gpt_path 进行修改
例如:

6.2 API 建立聊天机器人
完成了对 GPT-SoVITS 的修改,我们就可以写聊天机器人的代码了
准备工作
为了让程序自动播放音频,我们需要使用 pygame 这一 python 组件,在 runtime\Scripts 这一目录下打开终端,输入
.\pip.exe install pygame代码主体
在根目录下建立一个 chatbot.py 的 python 文件,编写代码如下
#-*- coding:utf-8 -*-
import requests
from openai import OpenAI
import json
import time
import pygame
client = OpenAI(
api_key="yourAPI",
base_url="https://api.moonshot.cn/v1"
)
pygame.init()
messages = []
while True:
prompt = """
你是一个语音助手
"""
characteristics = {
"role": "assistant",
"personality": "friendly",
"knowledge_base": "general",
"preferences": "helpful"
}
messages.append({"role": "system", "content": prompt})
messages.append({"role": "system", "content": json.dumps(characteristics)})
message = input("你: ")
messages.append({"role": "user", "content": message})
response = client.chat.completions.create(
model="moonshot-v1-8k",
messages=messages
)
speak_text = response.choices[0].message.content.strip() # 获取AI的回复文本
print(f"AI: {speak_text}")
params = {
"refer_wav_path": "GPT_weights\\1.wav",
"prompt_text": "最后我采取的方法也和缩壳乌龟一样",
"prompt_language": "中文",
"text": speak_text,
"text_language": "中英混合"
}
tts_service_url = f"http://127.0.0.1:9880/?refer_wav_path=GPT_weights%5C1.wav&prompt_text=最后我采取的方法也和缩壳乌龟一样&prompt_language=中文&text={{speakText}}&text_language=中英混合"
response_tts = requests.get(tts_service_url, params=params)
if response_tts.status_code == 200:
audio_data = response_tts.content
audio_filename = f"{time.time()}.wav"
with open(audio_filename, "wb") as f:
f.write(audio_data)
pygame.mixer.music.load(audio_filename)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
else:
print("TTS 请求失败,状态码:", response_tts.status_code)
messages.clear()其中,api_key需要自己去moonshot开发者平台进行注册使用。在这段代码中,首先通过调用了moonshot的API进行用户与AI之间的交流,之后将接收到的文本向GPT-SoVITS发送,GPT-SoVITS进行推理之后将音频文件在用户设备上进行播放。我们主要来看一下有关GPT-SoVITS的部分,首先是指定参考音频与音频的文本,语言。我将参考音频放到了GPT_weights下,并命名为1.wav
params = {
"refer_wav_path": "GPT_weights\\1.wav",
"prompt_text": "最后我采取的方法也和缩壳乌龟一样",
"prompt_language": "中文",
"text": speak_text,
"text_language": "中英混合"
}接下来就是向GPT-SoVITS发送请求
tts_service_url = f"http://127.0.0.1:9880/?refer_wav_path=GPT_weights%5C1.wav&prompt_text=最后我采取的方法也和缩壳乌龟一样&prompt_language=中文&text={{speakText}}&text_language=中英混合"
response_tts = requests.get(tts_service_url, params=params)如果能够正常发送请求,音频文件就会保存到根目录下并使用pygame自动播放,如果请求失败,就会报错
编写启动脚本
像之前一样,在根目录下新建一个启动.bat bat 文件,用记事本编辑
.\runtime\python.exe chatbot.py
pause使用
我们已经完成了对于GPT-SoVITS的改写以及聊天机器人代码的编写,我们只需要双击启动.bat就可以与拥有声音的AI进行交流了
成果展示如下:
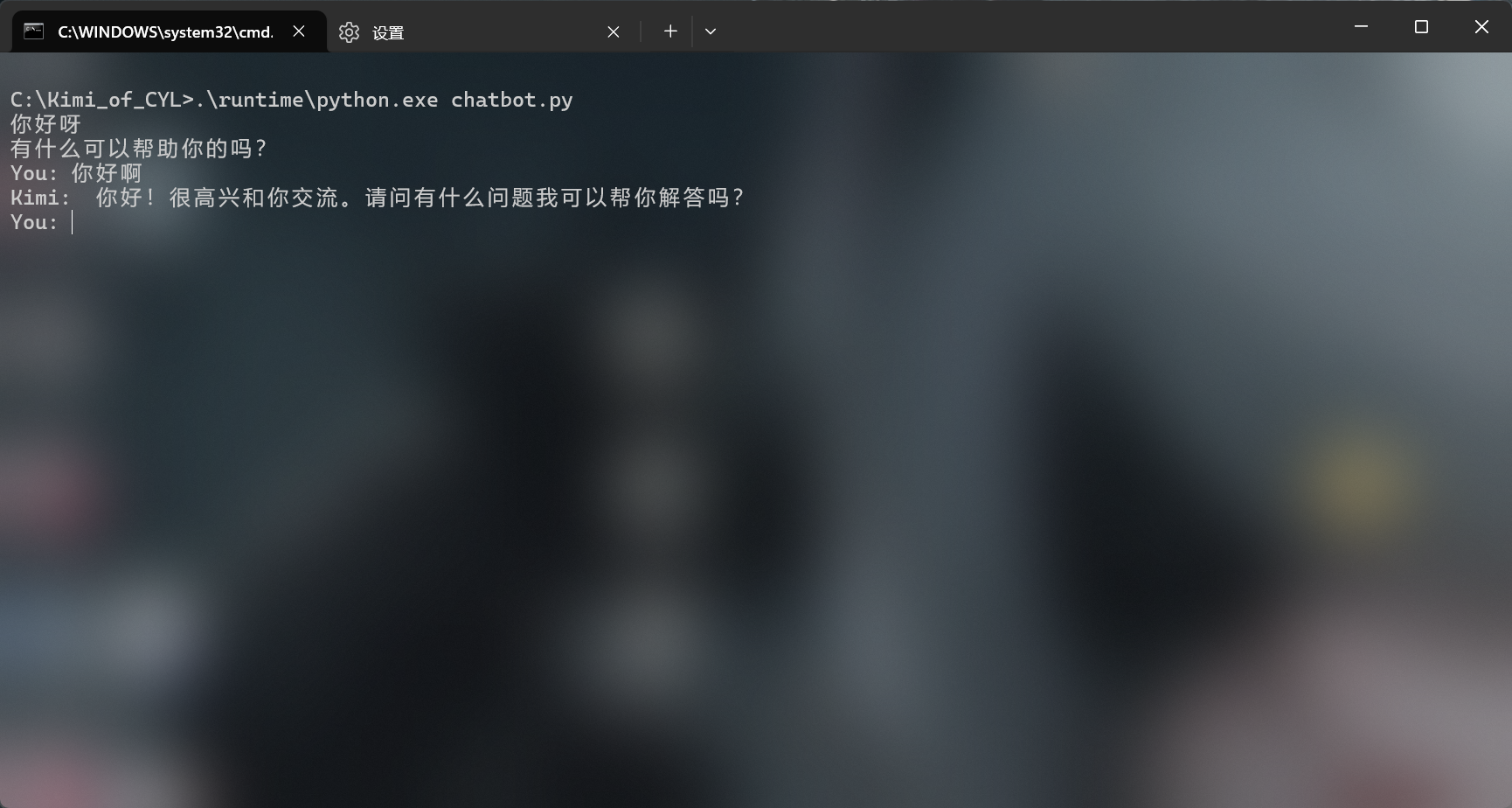


评论区